X2Video: Adapting Diffusion Models for Multimodal Controllable Neural Video Rendering
\(^*\) : Corresponding author
Paper |
Supplementary (87 demo videos)
Abstract
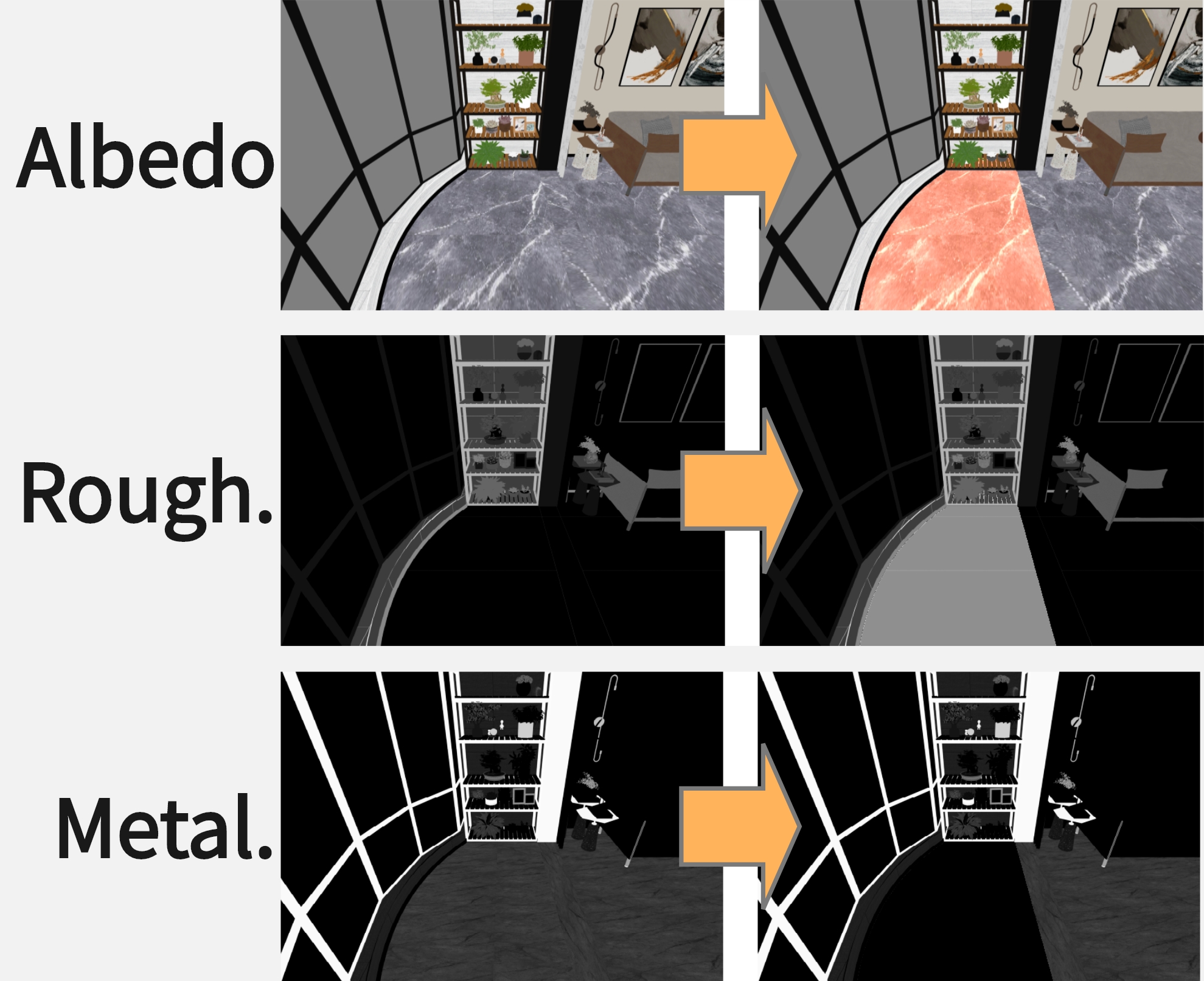
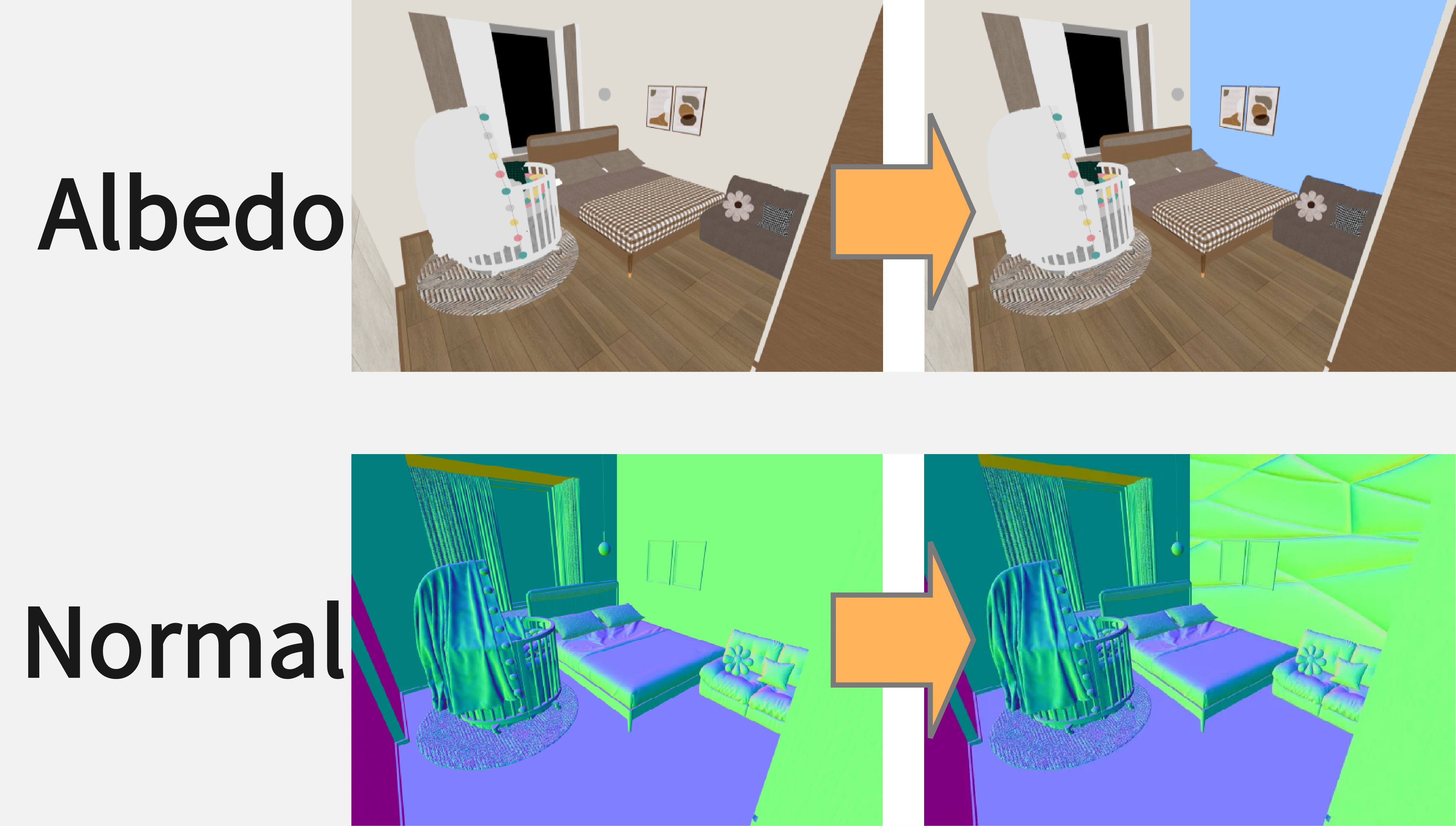
We present X2Video, the first diffusion model for rendering photorealistic videos guided by intrinsic channels including albedo, normal, roughness, metallicity, and irradiance, while supporting intuitive multi-modal controls with reference images and text prompts for both global and local regions. The intrinsic guidance allows accurate manipulation of color, material, geometry, and lighting, while reference images and text prompts provide intuitive adjustments in the absence of intrinsic information. To enable these functionalities, we extend the intrinsic-guided image generation model XRGB to video generation by employing a novel and efficient Hybrid Self-Attention, which ensures temporal consistency across video frames and also enhances fidelity to reference images. We further develop a Masked Cross-Attention to disentangle global and local text prompts, applying them effectively onto respective local and global regions. For generating long videos, our novel Recursive Sampling method incorporates progressive frame sampling, combining keyframe prediction and frame interpolation to maintain long-range temporal consistency while preventing error accumulation. To support the training of X2Video, we assembled a video dataset named InteriorVideo, featuring 1,154 rooms from 295 interior scenes, complete with reliable ground-truth intrinsic channel sequences and smooth camera trajectories.
Methodology


Comparisons
Qualitative comparisons with XRGB and SVD+CNet, where cyan frames highlight the temporal inconsistencies observed in XRGB. Purple frames indicate wrong colors or materials produced by SVD+CNet due to the lack of intrinsic knowledge. Red frames illustrate our model's ability to infer reflective surfaces with mirrored objects. Zoom-in is recommended for better visualization.
Multi-modal Controls
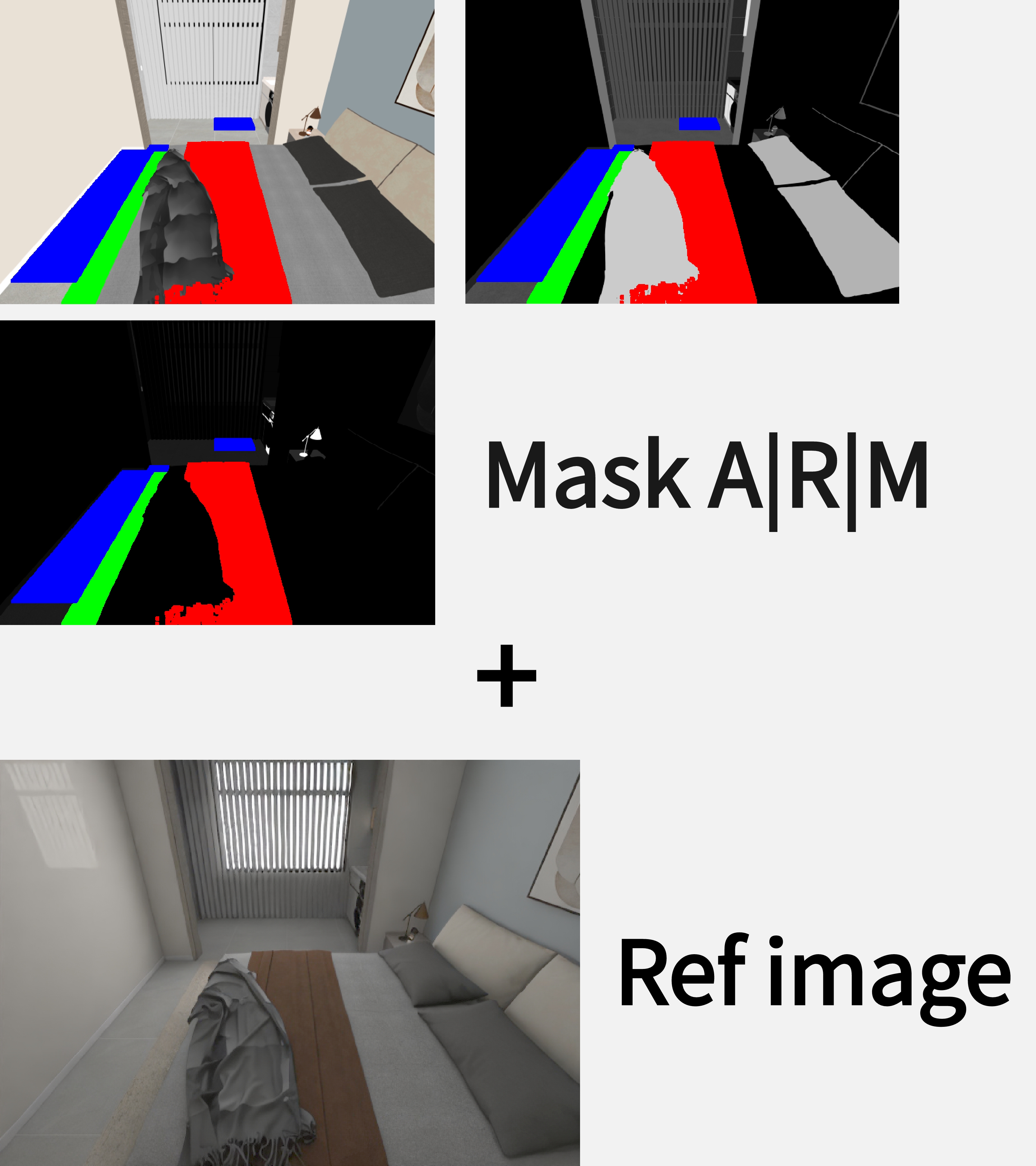
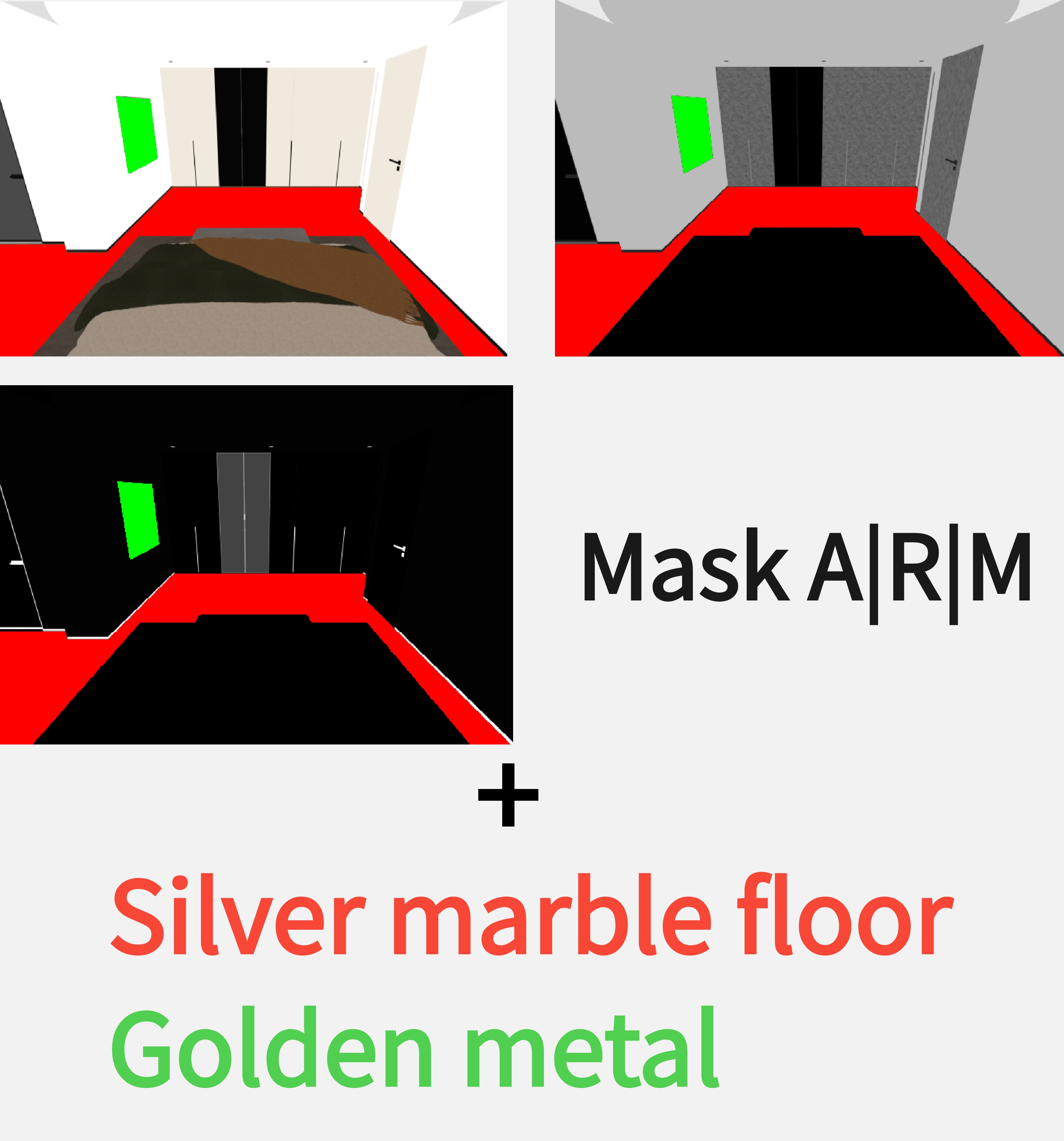
Multimodal controls with intrinsic channels, reference images, and text prompts on bota global and local regions.